Data Analysis Workshop
What is Webscraping?
Webscraping is the process of collecting data (information) from public websites that is then exported into an easier-to-read format. It can be done automatically or manually. Often, we are looking for external data sources that can be relevant to our learnings.
What are websites are made of?
We can think of it this way. In order to build a house, we must first understand what materials are used in the construction. In the same way to gather the relevant data from websites, we must first learn the way that websites are built.
Websites are created using HTML (Hypertext Markup Language), along with CSS (Cascading Style Sheets) and JavaScript. We are going to focus on the HTML. HTML, in a simple explanation, is the way that material is formatted/displayed over the internet. It allows creators to create and structure sections, paragraphs, and links with things like elements, tags, and attributes.
-
Tags: starting and ending parts of an HTML element
-
They will always begin and end with angle brackets (
<,>) -
Whatever is written inside the angle brackets is a tag.
-
Tags are like keywords with a distinctive meaning.
-
They also must be opened and closed in order to function.
-
ex: <a> content </a>
-
-
-
Elements: the content in between the tag
-
ex: <a> THIS IS THE ELEMENT </a>
-
-
Attributes: used to definite the characteristics of the HTML element in detail
-
They will only be found in the starting tag.
-
ex: <a align="right"> content </a>
-
-
When we are scraping, we need to find the tags that have the relevant information between them.
Tools to webscrape
There are several structures used to webscrape, such as requests, lxml, and beautifulsoup4, but we will be focusing today on using selenium. This will let us create a script to webscrape multiple pages to create our dataframe. Through selenium, the script can interact, scrape, and parse through the browser.
In getting started, we must choose a browser and it’s web driver.
-
Firefox: GeckoDriver
-
Chrome: ChromeDriver
-
Safari: SafariDriver
For this exercise, we will be using Firefox and Geckodriver.
We will need to download Selenium to use, so copy and paste the code below into your notebook.
from selenium import webdriver
from selenium.webdriver.firefox.options import Options
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
import uuid
firefox_options = Options()
firefox_options.add_argument("window-size=1920,1080")
# Headless mode means no GUI
firefox_options.add_argument("--headless")
firefox_options.add_argument("start-maximized")
firefox_options.add_argument("disable-infobars")
firefox_options.add_argument("--disable-extensions")
firefox_options.add_argument("--no-sandbox")
firefox_options.add_argument("--disable-dev-shm-usage")
firefox_options.add_argument('--disable-blink-features=AutomationControlled')
# Set the location of the executable Firefox program on Brown
firefox_options.binary_location = '/anvil/projects/tdm/bin/firefox/firefox'
profile = webdriver.FirefoxProfile()
profile.set_preference("dom.webdriver.enabled", False)
profile.set_preference('useAutomationExtension', False)
profile.update_preferences()
desired = DesiredCapabilities.FIREFOX
# Set the location of the executable geckodriver program on Brown
uu = uuid.uuid4()
driver = webdriver.Firefox(log_path=f"/tmp/{uu}", options=firefox_options, executable_path='/anvil/projects/tdm/bin/geckodriver', firefox_profile=profile, desired_capabilities=desired)Next, we will take a look at the website GoodReads
Highlight and right click the 1st book titled "The Alchemist", you should see a drop-down menu, go ahead and click Inspect.
You will see that at the bottom of the webpage, there is a new box that shows you the HTML code that builds the website.
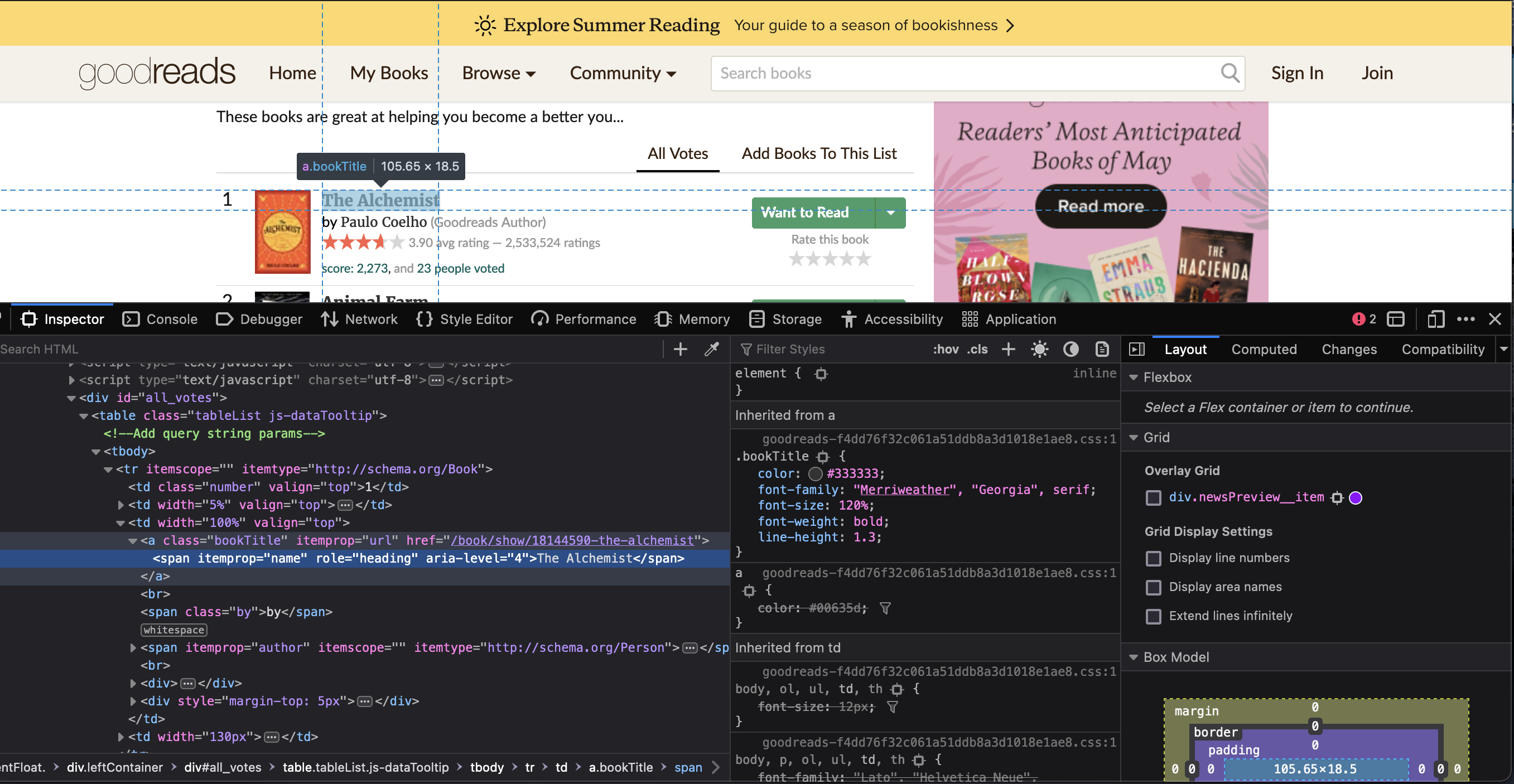
Here is where we will find all the information that we are looking for. You can copy and paste the script below.
driver = webdriver.Firefox(options=firefox_options,
executable_path='/anvil/projects/tdm/bin/geckodriver')
driver.get("https://www.goodreads.com/list/show/18645.Best_Books_That_Grow_You")
my_elements = driver.find_elements("xpath", "//a[@class='bookTitle']/span")
good_reads=[]
# Created a for loop that allows for us to keep adding more data to the end of the list
for element in my_elements:
good_reads.append(element.text)
# Prints out the list that we just created
print(good_reads)Try to use this code and edit it to find
-
the author’s names
HINT#author my_elements = driver.find_elements("xpath", "//a[@class='authorName']/span") -
the average ratings
HINT#Average Rating my_elements = driver.find_elements("xpath", "//span[@class='minirating']") -
the number of ratings
HINT#Number of Ratings my_elements = driver.find_elements("xpath", "//span[@class='minirating']")
When you get to the average ratings and the number of ratings you will need to make an adjustment, the code below takes the ratings information that you scraped (as connected strings) and separates them into the information that we need.
good_reads_rating = driver.find_elements("xpath", "//span[@class='minirating']")
my_avg_rating=[]
my_num_rating=[]
for string in good_reads_rating:
my_avg_rating.append(string.text.split(" ")[0])
my_num_rating.append(int(string.text.split(" ")[-2].replace(",","")))Notice that with the first code, we are only scraping the one page. If you print your data, you should see that you have 100 values BUT we want to scrape multiple pages. We do that by creating a for loop that edits the URL each time it hits the end of the page.
good_reads_2=[]
good_reads_2_authors=[]
for page in range(1,12,1):
page_url = f"https://www.goodreads.com/list/show/18645.Best_Books_That_Grow_Youpage={page}"
driver.get(page_url)
my_elements = driver.find_elements("xpath", "//a[@class='bookTitle']/span")
my_authors = driver.find_elements("xpath", "//a[@class='authorName']/span")
for element in my_elements:
good_reads_2.append(element.text)
for author in my_authors:
good_reads_2_authors.append(author.text)This code above will scrape multiple pages for the book titles, but now take this code and edit it so we can find the author’s names, average ratings, and number of ratings. Remember to split the rating strings just as we did previously
Now that we have all of the data, we want to take it and create a CSV file so that it is easy to look at, read, and analyze.
The first step to that is to take all of our data and create a neat dataframe.
import pandas as pd
dict = {'Title': good_reads_2, 'Authors': good_reads_2_authors, 'Average Rating': my_avg_rating_2, 'Number of Ratings': my_num_rating_2}
GoodReads2022 = pd.DataFrame(dict)
print(GoodReads2022)Once we have created the dataframe, we just need to export it into a csv file.
GoodReads2022.to_csv('GoodReads2022.csv')We did it!!! Hooray we took data and cleaned it up so that it becomes usable!